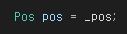
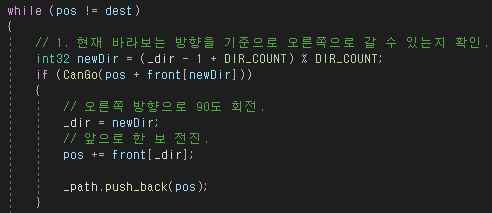
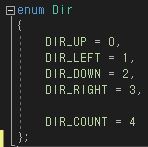
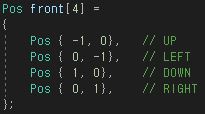
그래프 기초
그래프란?
현실 세계의 사물이나 추상적인 개념 간의 연결 관계를 표현한 것을 말한다.
그래프의 구성요소는 두 가지이며 다음과 같다.
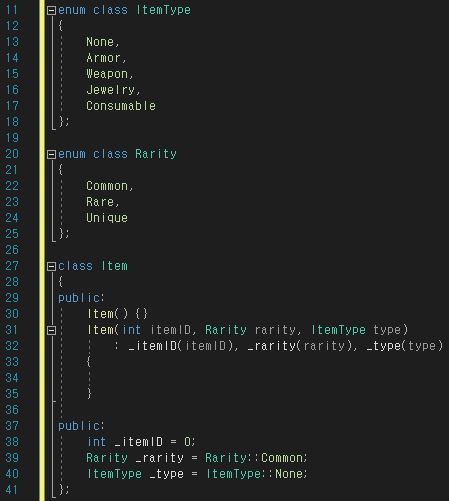
정점(Vertex) : 데이터를 표현한다.
간선(Edge) : 정점을 연결하는 데 사용한다.
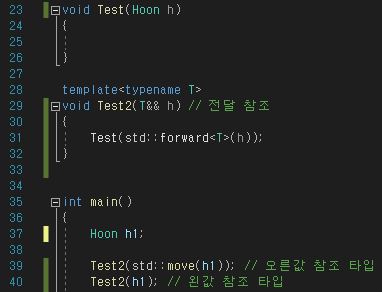
오늘은 C++을 이용해서 그래프를 간단하게 구현하는 실습을 해보겠다.
우선 말로만 그래프를 표현하려고 해도 한계가 있으니 이미지를 확인해보자
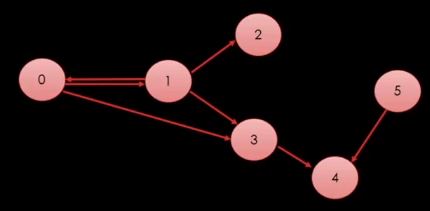
보는 바와 같이 원이 정점이며 원 사이에 화살표가 간선이다.
각각의 원들이 다른 원을 가리키고 있는 것을 알 수 있다.
이제 이것을 구현해보자
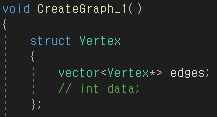
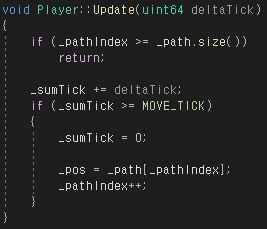
우선 CreateGraph 함수를 만들고 메인에서 해당 함수를 호출해서 그래프를 구현하는 동작을 하게 할 것이다.
함수 내에 정점 Vertex를 만들고 Vertex 내부에는 다른 Vertex를 가리키는 간선을 만들었다.
하나의 Vertex에서 여러개의 간선을 가질 수 있으므로 벡터로 만들어서 관리하는 모습이다.

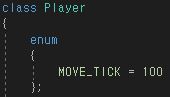
이제 Vertex를 선언하고 6개를 만들어주었다. 마찬가지로 여러 개의 Vertex를 벡터로 관리하는 모습이다.
그래프 개념 이미지를 참조하여 각각의 Vertex가 누구를 가리키고 있는지 간선에 저장하고 있다.
좀 더 자세히 말하면 0번 Vertex의 경우 1번과 3번 Vertex를 가리키고 있으므로 0번 Vertex 내부의
간선에 push_back을 이용해 1번과 3번 Vertex 주소를 넣고 있다.
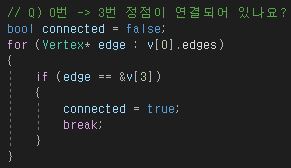
주석의 질문을 해결하기 위한 코드이다. bool 값을 하나 만들고, 반복문에 0번 Vertex가 가지고 있는 간선을 가지고 와서
임시 변수인 edge에 넣어준 후 if문을 통해 조건에 맞는지 확인하고 있다.
조건에 맞다면 0번 Vertex에 3번 Vertex가 연결되어 있다는 뜻이므로 bool 값을 true로 바꿔준다.
이번에는 다른 방법을 통해 그래프를 구현해보도록 하겠다.
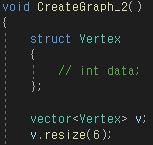
기존에는 Vertex안에 간선을 가지고 있는 형태였다면 이번에는 간선을 밖에서 관리하는 형태로 만들어보겠다.
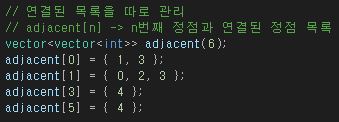
이중 벡터, 즉 이중 배열을 만들고 6개의 정점을 만든다.
n번째 정점에 이중 배열을 이용해서 간선을 넣어주는 형태이다.
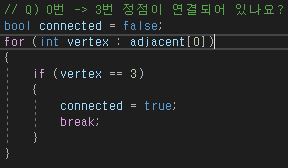
0번째 정점에 있는 간선을 꺼내와서 원하는 정점과 연결되어 있는지 확인하는 반복문이다.
각각의 구현 방법들이 상황에 따라 효율적인 상황이 다르기 때문에 잘 사용해야 한다.
이제 마지막으로 한 번 더 그래프를 다르게 구현해보도록 하겠다.
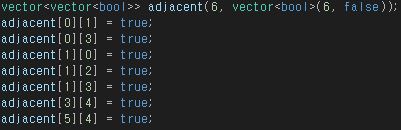
2-1 이미지처럼 연결된 간선을 따로 관리하지만 이번에는 6x6 크기의 2차원 배열을 통째로 만들고
기본 값을 false로 세팅한다. 그리고 연결된 간선만 true로 바꿔주면 된다.
이것의 특징은 메모리 소모가 심하지만 빠른 접근이 가능하다. 그래서 간선이 많은 경우 효율적이다.

빠른 접근이 가능하기 때문에 특정 정점이 연결되어 있는지 확인하는 것이 매우 쉽다.
'자료구조와 알고리즘' 카테고리의 다른 글
| 스택과 큐 개념 복습 (0) | 2022.07.27 |
|---|---|
| [선형 구조 기초] 배열, 동적 배열, 연결 리스트 복습/정리 (0) | 2022.07.26 |
| 오른손 법칙 (0) | 2022.07.26 |