algorithm
자료구조는 데이터를 저장하는 구조를 뜻하며
알고리즘은 데이터를 어떻게 사용할 것인가를 뜻한다.
C++에서는 다양한 알고리즘이 존재하는데 현업에서 자주 사용하는 알고리즘은 다음과 같다.
| find |
| find_if |
| count |
| count_if |
| all_of |
| any_of |
| none_of |
| for_each |
| remove |
| remove_if |
이제부터 하나씩 활용해보자.

find를 이용한 특정 데이터 찾는 방법이다.
배열의 시작과 끝을 넣어주고 찾는 정수를 넣어주면 된다.
반환 값은 iterator를 반환해주기 때문에 auto it 변수로 반환 값을 받아주었다.
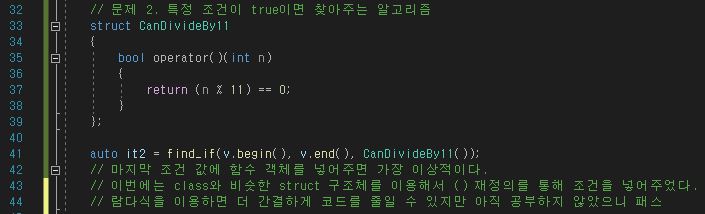
특정 조건에 맞는 데이터를 찾아주는 find_if 이다.
find_if는 배열의 시작과 끝을 넣어주고 마지막엔 함수 객체를 넣어주는 것이 가장 이상적이다.
이번에는 구조체 struct와 operator를 이용해서 조건을 넣어주었다.
람다식을 이용하면 좀 더 코드를 간결하게 할 수 있지만 이 부분은 람다식을 공부한 이후에 정리하도록 하겠다.

find와 거의 비슷한 형태를 가지고 있는 count이다.
특정 데이터의 개수를 찾아서 반환해준다.
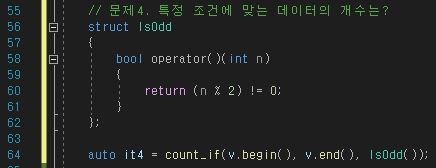
마찬가지로 특정 조건에 맞는 데이터의 개수를 반환해준다.
find_if와 크게 다른 점은 없다.
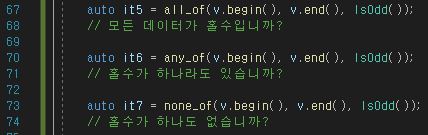
세 가지 기능은 묶어서 알아보자.
find나 count 형태와 같으며 사용자가 특정 조건을 넣어주면 true or false를 반환한다.
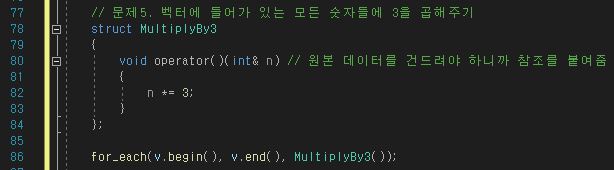
for_each는 위와 같은 활용 이외에도 데이터를 처음부터 끝까지 스캔하고 싶을 때 자주 사용된다.
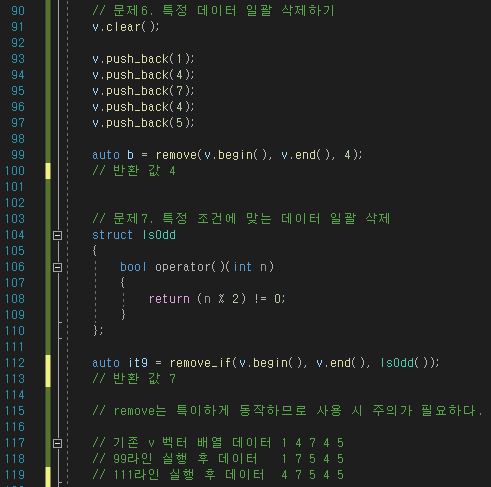
remove와 remove_if는 사용 시 주의가 필요하다.
동작이 조금 특이하게 일어나는데, 5-1 이미지를 자세히 보면 remove를 호출하고 난 뒤 생각했던 데이터가 아닌
이상한 데이터들이 들어가 있는 걸 확인할 수 있다.
기존 v 벡터 배열의 데이터는 직접 [ 1 4 7 4 5 ]로 세팅해주었다.
99번 라인에서 정수 4를 remove 해주고 난 뒤 v 벡터의 데이터를 살펴보면 다음과 바뀌어있다.
[ 1 7 5 4 5 ]
왜 이렇게 되었을까?
이것을 알기 위해선 remove가 특이하게 동작하는 것을 자세히 살펴보아야 한다.
해당 컴파일러에서 remove를 선택하고 F12를 통해 코드를 상세히 보거나 구글링을 통해 remove의 동작 방식을
살펴보게 되면 remove 같은 경우 특정 데이터 혹은 특정 조건에 해당하는 값을 없애는 것이 아니라 조건에 맞는
데이터 이외에 유효한 값을 앞으로 이동시키고 남은 유효하지 않은 데이터의 시작 위치를 반환하게 된다.
즉 99번 라인이 실행되면 기존 v 벡터의 데이터 [1 4 7 4 5 ] 중에서 유효한 값인 1, 7, 5의 값이 앞으로 이동하게 되고
반환 값으로 불필요한 데이터(4, 5)의 시작 위치인 4의 주소를 반환하게 된다.
remove_if 또한 마찬가지이다. 조건으로 홀수를 삭제하도록 넣어주었고 [ 1 7 5 4 5 ] 데이터에서 4를 제외한
전부가 홀수이기 때문에 유효한 값인 4만 맨 앞으로 이동하게 되고 불필요한 데이터(7, 5, 4, 5)의 시작 위치인
7의 주소를 반환하게 된다.
remove를 하게 되어도 실제 벡터에서 데이터가 삭제되는 것이 아니기 때문에 정말로 불필요한 데이터를
삭제하고 싶다면 다음과 같이 erase를 사용하도록 하자

불필요한 데이터의 시작 위치인 7부터 벡터 끝까지 데이터를 삭제하는 코드이다.
'프로그래밍 언어 공부 > C++' 카테고리의 다른 글
| [Modern C++] 중괄호 초기화 { } (0) | 2022.07.14 |
|---|---|
| [Modern C++] auto (0) | 2022.07.14 |
| STL - deque (0) | 2022.07.11 |
| STL - list (0) | 2022.07.08 |
| STL - vector (0) | 2022.07.05 |