vector
STL (Standard Template Library)에서 가장 많이 활용되는 vector에 대해 알아보자.
(STL의 개념은 프로그래밍할 때 필요한 자료구조나 알고리즘들을 템플릿으로 제공하는 라이브러리이다.)
vector는 STL의 컨테이너 중 하나이다. 여기서 컨테이너란 자료구조를 뜻하며 쉽게 말하면
데이터를 저장하는 객체이다.
vector는 워낙 다양한 기능들을 가지고 있기 때문에 원리에 대한 이해가 중요하다.
- vector의 동작 원리 (size / capacity)
- 중간 삽입/삭제
- 처음/끝 삽입/삭제
- 임의 접근
위와 같이 원리에 대해 공부해보자.
vector의 동작 원리 (size / capacity)
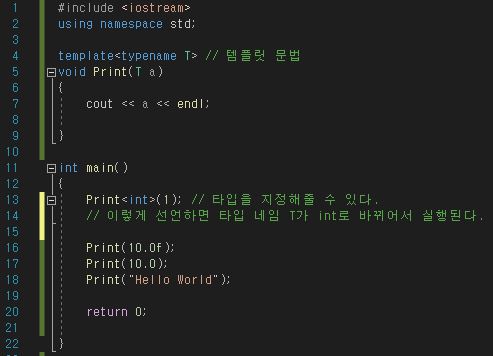
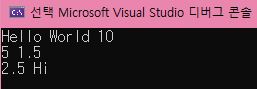
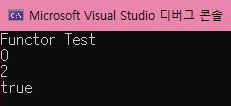
 1-1. vector 기초
1-1. vector 기초
 1-2. 결과
1-2. 결과
vector는 동적 배열로 동작을 하게 된다.
일반적인 배열은 시작 시에 사이즈가 정해지고 나중에 해당 사이즈의 변경이 필요할 때
마음대로 바꿀 수 없다는 단점이 존재한다. 이러한 단점을 보완하는 것이 동적 배열이다.
즉 배열을 유동적으로 사용하는 것이 가능하다.
그러면 어떻게 배열을 유동적으로 사용하는 것일까? 이 부분에 대한 이해가 중요한 포인트이다.
일단 두 가지 로직이 존재한다.
1) 처음에 메모리를 할당할 때 여유분을 두고 할당한다.
2) 여유분까지 메모리가 꽉 찼다면 메모리를 추가적으로 증설한다.
위 두 가지 로직을 기준으로 동작하게 되며 해당 사항을 좀 더 이해하려면 vector에서
size와 capacity를 살펴봐야 한다.
size는 실제 사용 데이터 개수를 나타낸다.
capacity는 여유분을 포함한 총 용량 개수를 나타낸다.
size는 말 그대로 실제 사용 데이터 개수를 나타내기 때문에 데이터가 증가하는 대로
차례대로 증가하지만 capacity 같은 경우 총 용량을 나타내기 때문에 기존 capacity에서 1.5배 혹은 2배
만큼의 추가적인 여유분을 포함해서 나타내게 된다.
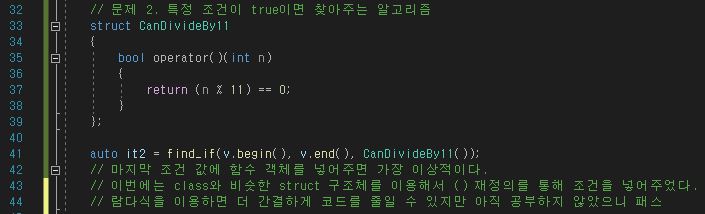
ex size
1, 2, 3, 4, 5, 6, 7, 8....
ex capacity
1, 2, 3, 4, 6, 9, 13, 19, 28, 42, 63....
위에서 메모리를 추가적으로 증설한다고 했는데 조금 더 자세히 말하자면 여유분까지 메모리가 꽉 찼다면
다른 메모리 장소에 이동해서 좀 더 큰 크기의 메모리를 할당해주고 기존의 값을 그대로 복사해오며 기존의 할당된
메모리는 반환된다. 하지만 기존의 할당된 메모리의 크기가 아주 크다면 복사해오는 것 자체가 매우 부담되는 일이고
또한 여유분들 어느 정도로 잡아놔야 하는지 예측할 수 없는 부분이기 때문에 곤란하다.
이러한 문제를 해결하기 위해 동적 배열에서는 기존 capacity 크기에서 몇 배씩 큰 크기만큼의
여유분을 잡아주게 되는 것이다.
크기 조정 함수
다음은 초반 capacity의 크기를 지정해줄 수 있는 함수이다.
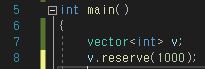 capacity 크기 조정
capacity 크기 조정
처음부터 capacity를 너무 작게 할당해주면 비효율적으로 복사가 계속 일어나게 되므로 이것을 해결하기 위해
사용자가 원하는 크기만큼 초반에 메모리를 할당하게 해주는 함수이다.
다음은 size의 크기를 지정해줄 수 있는 함수이다.
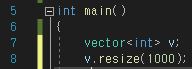 size 크기 조정
size 크기 조정
reserve와 비슷한 개념으로 이번에는 size, 즉 실제 사용 중인 데이터 개수를 지정해 줄 수 있는 함수이다.
resize를 하게 되면 자동적으로 capacity의 크기 또한 같은 크기로 바뀌게 된다.
resize 이후에는 size와 capacity가 동일하게 되므로 이후에 push_back 같은 벡터 함수를 사용하게 되면
여유분을 추가하게 되며 복사가 일어난다. 그렇기 때문에 resize로 설정한 크기를 사용하고 싶다면
push_back이 아니라 일반 배열 사용하는 것처럼 데이터를 넣어서 사용하면 된다.
다음은 vector 선언과 동시에 resize를 해주는 방법이다.
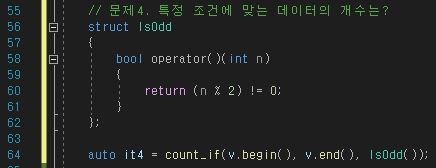
 선언과 동시에 resize 해주기
선언과 동시에 resize 해주기
7번 라인의 뜻은 v 벡터를 선언함과 동시에 1000 크기만큼 resize를 해주고 해당 초기 값을 전부 0으로
해주겠다는 뜻이다.
8번 라인은 위에서 선언했던 v 벡터를 v2 벡터에 그대로 넣어줘서 같은 resize 및 초기 값을 가지도록 한 것이다.
할당된 메모리 반환
할당된 size와 capacity를 날려주는 방법은 다음과 같다.
v.clear(); // size, 실제 사용 중인 메모리를 모두 반환하는 함수 단 capacity는 그대로 유지
vector<int>().swap(v); // 임시적인 벡터를 잠시 생성하고 swap 함수를 통해 기존의 v 벡터와 메모리를 swap 한다.
해당 라인을 벗어나면 임시로 만들었던 벡터는 사라지고 해당 임시 벡터의 메모리가 v 벡터로 들어갔기 때문에
size와 capacity 모두 0이 된다. 실전에서는 잘 사용하지 않는 꼼수 같은 개념이지만 알아두자.
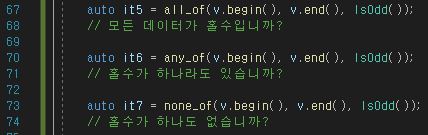
★ 삽입, 삭제와 반복자 개념
중간 삽입/삭제, 처음/끝 삽입/삭제를 알아보자.
우선 삽입, 삭제를 이해하기 위해선 반복자를 알아야 한다.
반복자는 STL의 구성물 중 하나이며 컨테이너마다 반복자를 하나씩 들고 있다.
쉽게 생각해서 포인터와 유사한 개념이다. 컨테이너의 데이터를 가리키고, 다음/이전 데이터로
이동이 가능하다.
 2-1. 반복자
2-1. 반복자
이미지 2-1과 같이 포인터와 유사하게 사용할 수 있다.
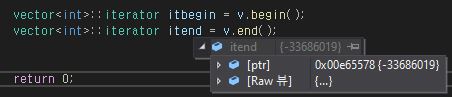 3-1. 벡터 end 함수 특성
3-1. 벡터 end 함수 특성
벡터의 begin 함수의 경우 벡터 배열의 시작 지점 주소를 가지고 있었지만
end 함수 같은 경우 벡터 배열의 유효한 값이 들어있는 끝 지점이 아닌 배열 자체가 끝나는 지점의 주소를 갖기 때문에
해당 end 함수는 사용 시에 주의가 필요하다.
그러면 어떻게 사용해야 할까?
 4-1. begin, end 함수 사용법
4-1. begin, end 함수 사용법
이미지 4-1 라인 30~33번까지 실전에서도 많이 사용하는 방법이다.
begin으로 배열 시작 주소를 it 변수에 넣어주고 end 함수가 될 때까지 1씩 증가시키면서
배열 내용을 출력하는 형식이다. 배열 안에 데이터로 접근하기 위해 포인터를 붙여주었다.
30번 라인 끝 부분에 it++ 보다는 성능적으로 ++it가 약간 더 우위에 있다.
그러니 되도록이면 ++it를 사용하도록 하자.
이미지 4-1 라인 30~33번을 보면 iterator를 사용하니 뭔가 복잡해 보인다.
그러면 왜 이렇게 사용하는 것일까
이유는 간단하다 iterator는 벡터뿐만 아니라 다른 컨테이너에도 공통적으로 존재하는 개념이다.
그렇기 때문에 라인 30~33번처럼 만들게 되면 상황에 따라 컨테이너를 부분을 수정해서 수월하게
사용할 수도 있기 때문에 해당 방법이 권장된다.
다음은 일반 iterator 이외에 다른 기능을 하는 iterator이다.
 5-1. reverse_iterator / const_iterator
5-1. reverse_iterator / const_iterator
라인 35번의 reverse는 배열의 시작과 끝을 반대로 출력하기 위한 reverse이다.
그리고 라인 40번의 const는 이미 알다시피 값을 변경할 필요가 없을 때 상수화 시켜주기 위한
const이다. 이외에도 다양한 기능들이 존재함.
★ 이제부턴 삽입/삭제에 관해 알아보도록 하자
우선 벡터 같은 배열 형식은 중간 삽입/삭제가 매우 비효율적이다.
이유는 배열의 특성 때문인데 일단 배열은 원소(데이터)가 하나의 메모리 블록에
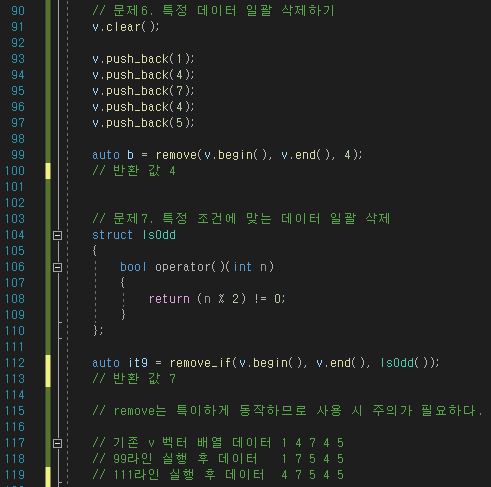
연속하게 저장된다는 특성을 가지고 있다. 그런데 중간에 데이터를 삽입하거나 삭제하게 되면
배열에 연속하게 저장되어 있던 다른 데이터들을 모두 한 칸씩 밀거나 당기는 상황이 발생하게 된다.
만약 여기서 저장된 데이터가 아주 크다면 매우 비효율적인 이동을 하게 된다는 것이다.
처음/끝 삽입/삭제 또한 비슷한 개념이다.
처음에 데이터를 삽입/삭제 하게 되면 기존에 저장되어 있던 데이터들을 모두 한 칸씩 밀어내야 하거나
당겨야 하는 상황이 발생하기 때문에 비효율적이고 반대로 끝 삽입/삭제 같은 경우 배열 끝부분에 데이터를
삽입하거나 삭제해도 기존 데이터의 이동이 발생하지 않기 때문에 효율적인 방법이라고 할 수 있다.
임의 접근은 배열에서의 개념과 동일하다.
벡터 또한 배열이기 때문에 배열의 특정 위치에 있는 데이터에 접근하여 해당 데이터를 사용하거나
수정하는 일이 가능하다. (다른 컨테이너는 임의 접근 불가능)
ex) v[3] = 1; // 4번째 데이터의 값을 1로 수정
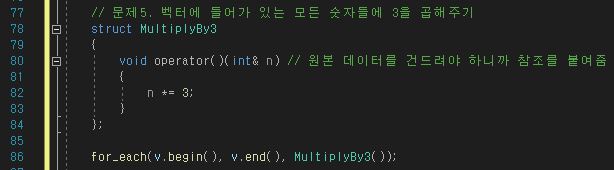
비효율적이라곤 하나 상황에 따라 중간 삽입이 필요한 경우도 있다.
그럴 때 사용하는 것이 vector의 insert 함수이다.
 6-1. insert / erase 함수
6-1. insert / erase 함수
위의 이미지 같이 사용할 수 있다. insert는 삽입이고 erase가 삭제하는 함수이다.
중요한 부분은 삽입/삭제 이후에 그대로 끝나는 것이 아니라 반환 값이 있다는 점이다.
삽입/삭제가 일어났을 경우 해당 위치를 반환 값으로 뱉어주기 때문에 해당 반환 값을 이용하는 방법도
존재한다.
이번에는 반환 값을 이용하는 방법이다.
처음부터 배열의 데이터를 쭉 스캔하면서 3이라는 데이터가 있으면 해당 3을 가지고 있는 부분을
일괄 삭제하는 방법을 알아보자. 실전에서도 자주 사용되는 방법이다.
 7-1. 스캔 후 특정 데이터 일괄 삭제(에러발생 버전)
7-1. 스캔 후 특정 데이터 일괄 삭제(에러발생 버전)
이미지 7-1 처럼 코드를 짜면 에러가 발생한다.
왜 에러가 발생하는 것일까?
에러가 발생한 곳은 iterator 삭제 이후 그 다음 값을 스캔하기 위해 호출하는 부분에서 발생했다.
에러가 발생한 이유는 iterator가 가지고 있는 ptr 값 이외에 다양한 정보(어느 컨테이너에 소속되어 있는지 등등)도
다 같이 삭제되기 때문에 삭제 이후로는 어떠한 형태로도 사용되면 안되는데 for문에 의해 스캔이 계속 되기 때문에
에러가 발생한 것이다.
그러면 어떻게 해결할 수 있을까?
답은 삽입/삭제 이후에 반환 값을 활용하는 것이다.
 7-2. 스캔 후 특정 데이터 일괄 삭제(정상 버전)
7-2. 스캔 후 특정 데이터 일괄 삭제(정상 버전)
라인 54번을 보면 반환 값, 즉 삭제 이후에 해당 위치를 다시 it1에 넣어주는 모습이다.
코드를 자세히 보면 조금 이상한 점이 있다. 라인 50번 맨 마지막에 ++it1이 라인 56번으로 이동하였다.
그 이유는 스캔에서 놓치는 부분이 있기 때문이다.
삭제 이후에 위치를 다시 it1에 넣어주었으면 나머지 데이터들은 빈자리를 채우면서 당겨오게 된다.
그래서 삭제 위치에 바로 옆에 있던 데이터가 들어오게 되고 해당 데이터는 스캔을 하지 못하고 다음 데이터로
스캔이 이동하게 된다는 것이다. 그래서 ++it1를 else로 넣어줌으로써 삭제가 일어나지 않았으면 ++을 진행하고
삭제가 발생했으면 ++을 하지 않고 삭제한 위치에 새로 들어온 데이터를 다시 한번 스캔해주는 것이다.